

* 本文作者:nightmarelee,本文属FreeBuf原创奖励计划,未经许可禁止转载
漏洞的出现对于应急响应的同学而言就是一场战争,往往需要紧急的编写脚本,下发扫描,有时甚至需要到Git的存储机器上对代码来个全身检查,最后确定相关的负责人。整个流程执行完成,花费的时间大概是1~2天,而且每次漏洞的出现都需要执行重复的操作。一直设想有没有针对漏洞出现的一键排查工具,通过输入出现漏洞的软件、组件名称,自动完成漏洞软件或组件的排查。下文将根据本人在资产收集中构建的漏洞一键排查系统谈谈漏洞的快速排查问题。
1、系统介绍
目前该系统包含两项应急排查功能,分别是:主机软件排查、依赖插件排查,是应急响应中时长需排查的项目,下面分别对其使用及效果进行简要介绍。
1.1 主机软件排查
在搜索输入框中输入要搜索软件的名称,点击搜索,下面的文本区域就会展示包含被搜索软件的主机信息(被遮挡部分)及软件版本信息,使用效果如下图所示,基于软件版本及主机信息就能快速定位问题主机。
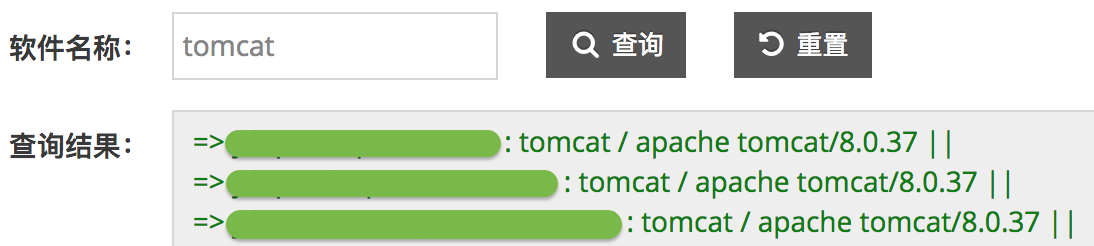
1.2 依赖插件排查
目前大型互联网公司多使用Java作为开发语言,因此这里主要介绍针对Java的依赖插件进行排查。同样在搜索输入框中输入要搜索软件的名称,点击搜索,下面的文本区域就会展示包含被搜索依赖插件的Git仓库信息(Project/Repository)、版本信息、仓库负责人信息,使用效果如下图所示。

上面展示了该排查系统的一个基本概况,下面将对其具体的实现进行详细的说明。
2、主机软件排查
主机软件排查是在收集线上主机资产信息衍生而来,线上主机的信息可以依赖公司相关资产记录获取,这个比较容易获取,但是在漏洞排查过程中最为重要的信息便是每个主机所安装的软件及版本信息。为获取这部分信息,我们需要针对常见软件编写获取其软件名称及版本信息的shell脚本,并下发到每个线上主机,并将产生的日志信息定期回收归总,形成一份完整的主机软件信息。通过公司资产的记录及这份主软件信息,就可以轻松的构建起针对主机软件出现漏洞时的应急排查。但是这种排查比较依赖于我们所以收集的主机软件信息,因此能否收集尽可能全面的软件版本信息对我们系统的工作效果至关重要。
3、Java依赖插件排查
对于Java依赖插件的排查是对公司stash仓库资产进行整理时衍生而来,以前进行排查的方式是在存储Git代码的机器上运行Python脚本,通过GitPython包排查存在风险的依赖插件,这种排查方式存在很大的风险。而且需要每次漏洞出现后在特定机器上运行脚本进行排查,时效性很难得到保障,如果能够对代码进行进行实时的监控并将其依赖的插件信息抽出,需要进行漏洞排查时,只需查询事先整理的数据库,就能快速的完成漏洞排查的工作。
目前几乎所有的互联网公司都使用stash进行代码管理,当然还有不少公司依然是SVN的坚定支持者。stash管理的代码会包含多个Project,每个Project中又包含多个Repository,实际的代码便是储存在Repository中,也就是我们常说的Git仓库。对stash进行监控,我总结为以下几个步骤。
3.1 获取登录状态
对stash进行访问,肯定是需要进行认证后方能访问,stash里的访问登录一般都是接入公司的认证体系,因为每个公司的认真方式都是不同的,需要我们使用中间人工具拦截并分析认证的通信消息,然后对这些交互消息进行逐条分析,并使用代码实现自动化的模拟登录,一般stash的认证后的凭证是生成一个访问Git的session_id。进行协议逆向这块是一个相当繁琐的过程,需要从上百条交互信息中筛选出认证需要的信息,而且一次认真需要多次交互,比如我分析的这个系统就需要多达八次的交互才完成一次认证,所以需要耐着性子慢慢分析整个协议交互流程。
3.2 获取Project访问权限
stash一般存在权限认证,我们只能访问到很少的一部分代码,为了能够监控所有的代码,需要仓库的访问权限。对于仓库的访问权限添加,最好不要使用自己的账户添加访问权限,因为如果你一旦离职,后面接手的同学还要从新添加一遍,不利于系统的维护。这里我们最好创建虚拟账户,使用虚拟账户添加代码的访问权限,而且添加代码权限是添加Project的Read权限,有些负责Project同学常常以为是添加Repository的Read权限,所以会向你抱怨,几千个Repository怎么添加啊。
3.3 stash访问说明
搞定了上面两步,这时我们就需要摸清访问stash中具体代码(Repository)时的通信方式,没分析前我一直心中暗暗嘀咕,估计又要写大量的爬虫代码来从网页上一点点的抠代码了,想想都是泪。不过仔细查看其交互流程后发现,stash是使用接口的方式获取数据,将数据以JSON格式返回,然后渲染到页面上,这一点确实非常之方便,不用再一点点的去页面上抠信息,具体的交互信息大家自己那中间人工具拦截看一看吧。
3.4 pom.xml文件获取
为什么这里要单独获取pom.xml文件,因为目前大部分Java项目的依赖都在这个文件中进行配置,当然很多Java的小菜鸟(such as me)都不知道咋用,尴尬。获取该文件的方式废话不多说,直接上代码。
def scan_repository_file(repositories_dict):
'''
扫描Git仓库中所有的文件及目录
:return:
'''
limit = 10000
branch = 'master'
# 用于储存pom.xml文件地址
pom_dict = {}
headers = {
'Cookie': cookie
}
for repo_name in repositories_dict.keys():
try:
print u'正在扫描仓库: ' + repo_name
owner, link_url, language = repositories_dict.get(repo_name)
url = base_url + link_url + '/?at=' + branch + '&limit=' + str(limit)
response = requests.get(url=url, headers=headers)
content = json.loads(response.content)
if content.__contains__('children'):
values = content.get('children')['values']
# 判断是否包含pom.xml文件
contain_pom = False
for v in values:
name = v.get('path')['name']
type_ = v.get('type')
if type_ == 'FILE' and name == 'pom.xml':
contain_pom = True
if contain_pom:
for v in values:
name = v.get('path')['name']
type_ = v.get('type')
if type_ == 'DIRECTORY':
_scan_dir(url, name, headers, pom_dict, repo_name)
else:
if name == 'pom.xml':
ll = url.split('?at=')
pom_url = ll[0] + '/pom.xml' + '?at=' + ll[1]
# print repo_name
# print pom_url
if pom_dict.__contains__(repo_name):
old = pom_dict.get(repo_name)
new = old + [pom_url]
pom_dict[repo_name] = new
else:
pom_dict[repo_name] = [pom_url]
# print pom_dict
else:
continue
except Exception, e:
print e
continue
return pom_dict
代码的结构比较简单,就是通过构造Repository的地址并访问,判断其中是否存在pom.xml文件,如果存在,则通过递归扫描,找出该仓库中所有的pom.xml文件并储存地址,然后返回所有的pom.xml文件地址。递归扫描的函数(_scan_dir)如下所示。
def _scan_dir(url, dir_name, headers, pom_dict, repo_name):
'''
该方法是一个递归方法,用于遍历git上的文件夹
:return:
'''
url_list = url.split('?at=')
new_url = url_list[0] + '/' + dir_name + '?at=' + url_list[1]
response = requests.get(url=new_url, headers=headers)
content = json.loads(response.content)
# print json.dumps(content)
# print new_url
values = content.get('children')['values']
for v in values:
try:
name = v.get('path')['name']
type_ = v.get('type')
if type_ == 'DIRECTORY':
_scan_dir(new_url, name, headers, pom_dict, repo_name)
else:
if name == 'pom.xml':
ll = new_url.split('?at=')
pom_url = ll[0] + '/pom.xml' + '?at=' + ll[1]
# print repo_name
# print pom_url
if pom_dict.__contains__(repo_name):
old = pom_dict.get(repo_name)
new = old + [pom_url]
pom_dict[repo_name] = new
else:
pom_dict[repo_name] = [pom_url]
# print pom_dict
except Exception, e:
print e
continue
3.5 pom.xml文件解析
获取XML文件后,我们就需要对XML文件进行解析,初期构想的方式肯定是需要对XML文件进行解析获取其对象,然后再一点点抠里面的依赖项目,后来仔细观察整个XML文件stash的返回方式及文件特征,发现只需要进行简单的字符串解析就能拿到我们需要的内容,直接上代码瞅瞅。
def _scan_pom_dependencies(pom_url):
'''
该方法用于扫描Java的pom.xml文件,获取其中的dependency相关参数
:param pom_url: pom.xml文件URL地址
:return:
'''
headers = {
'Cookie': cookie
}
response = requests.get(url=pom_url, headers=headers)
pom_content = json.loads(response.content)
dependency_dict = {}
property_dict = {}
if pom_content.__contains__('lines'):
pom_content_list = pom_content.get('lines')
in_dependencies = False
in_dependency = False
in_properties = False
# version_pattern = re.compile(r'<[a-zA-Z0-9\.\/]+>')
# u'spring-jms': u'${spring.version}'这种版本信息,在properties中遍历信息
for line in pom_content_list:
try:
line_content = line.get('text').strip()
if line_content != '' and line_content.find('<!--') == -1:
if line_content.find('<properties>') != -1:
in_properties = True
if line_content.find('</properties>') != -1:
in_properties = False
if in_properties and line_content != '<properties>':
ll2 = line_content.split('</')
v_name = ll2[1].split('>')[0]
v_value = ll2[0].split('<' + v_name + '>')[1]
property_dict['${'+v_name+'}'] = v_value
except Exception, e:
print e
continue
artifactId = None
version = None
for line in pom_content_list:
try:
line_content = line.get('text').strip()
if line_content.find('<dependencies>') != -1:
in_dependencies = True
if line_content.find('</dependencies>') != -1:
in_dependencies = False
artifactId = None
version = None
if line_content.find('<dependency>') != -1:
in_dependency = True
if line_content.find('</dependency>') != -1:
in_dependency = False
artifactId = None
version = None
if in_dependencies and in_dependency:
if line_content.find('<artifactId>') != -1 and line_content.find('</artifactId>') != -1:
artifactId = line_content.split('<artifactId>')[1].split('</artifactId>')[0]
if line_content.find('<version>') != -1 and line_content.find('</version>') != -1:
version = line_content.split('<version>')[1].split('</version>')[0]
if artifactId != None and version != None:
if property_dict.__contains__(version):
version = property_dict.get(version)
dependency_dict[artifactId] = version
artifactId = None
version = None
except Exception, e:
print e
continue
return dependency_dict
由于pom.xml文件中有些依赖(dependency)的版本信息是通过property属性中定义的,因此在解析整个pom.xml文件前我们把所有property属性解析出来,在扫描插件版本信息时,如果与property属性一致,则直接替换成property属性的值。最终返回Repository中所有的依赖插件及其版本信息。
3.6 Repository负责人获取
完成依赖插件的解析工作,并没有结束,因为漏洞排查的最终目的是对漏洞问题进行整改,因此我们必须确定代码的最终负责人。在访问Repository的时候,stash会将该仓库的负责人信息回传,但是这个负责人只是仓库的创建者,如果这个创建者离职,Repository的负责人并不会改变,这将会为我们漏洞推动修复工作带来很大的困扰。为此我们将commit代码到该仓库的人都认为是该Repository的负责人,这样就不会再漏洞推动修复的时候找不到人。这部分信息位于stash中events信息(新版)中,代码如下所示。
def _get_eventers(project_name, repository_name):
'''
由于直接从Repository中获取的owner信息可能存在离职的情况,因此需要从events数据中获取上传过代码的相关人员,方便追踪
:param project_name: Project名称
:param repository_name: Repository名称
:return:
'''
eventer = []
limit = 50
headers = {
'Cookie': cookie
}
url = base_url + 'CodeEvents/projects/' + project_name + '/repos/' + repository_name + '/PushedEvents/0/' + str(limit)
response = requests.get(url, headers=headers).json()
if response.__contains__('values'):
values = response.get('values')
for value in values:
name = value.get('author')['name']
if not eventer.__contains__(name):
eventer.append(name)
return eventer
4、总结
至此我们已经完成整个系统的讲解,由于主机部分的信息是从其它同学那里直接拉取过来的,因此讲解的较少。针对依赖插件的排查,根据stash获取Java相关依赖信息的代码已整理成工具开源,见github:https://github.com/blackarbiter/git-dependency,由于版本原因可能造成工具无法使用的情况,请针对公司的stash版本进行修正。如有任何问题欢迎留言/私信指正。
* 本文作者:nightmarelee,本文属FreeBuf原创奖励计划,未经许可禁止转载










暂无评论内容